[ Table Of Contents ] [ Previous
Chapter ] [ Previous Section ] [ Next
Chapter ] [ Next Section ]
6. OGIS Information Communities Model - Managing Data Heterogeneity
6.1 Introduction
The pluggable computing model for distributed geoprocessing grew out of discussions
about how general models of component-based and common interface-based distributed
computing could be applied to geoprocessing and geodata access. We now present a concept,
the OGIS Information Communities Model, which grew out of discussions about how the
notoriously difficult problem of federated databases could be partially and practically
solved for the purpose of sharing information between databases that contain complex
geodata with inconsistent geodata feature definitions.
Much of the stimulus for the OGIS Project comes from a need to share geographic
information more effectively between individuals and organizations who not only store and
manipulate geographic data in different ways on different computer systems, but who think
about, talk about, and visualize geography in very different ways. The OGIS Information
Communities Model helps solve the human problem of communication between communities who,
by necessity or chance, describe geographic features in different ways. To an ecologist,
highways are barriers with particular characteristics affecting populations of plants and
animals. To a civil engineer, highways are legally bounded public properties with
particular pavement structures, drainage problems, load requirements, etc. An ecologist
and a civil engineer might exchange data easily because they use the same software,
but they won't define highways in the same way, so exchange of information will be
limited.
The OGIS Information Communities Model was devised to enable groups such as ecologists
and civil engineers efficiently manage the semantics (or feature schema mismatches) of
their own geodata collections and get maximum benefit from each other's geodata
collections, despite semantic differences.
An Information Community is a collection of people (a government agency or group of
agencies, a profession, a group of researchers in the same discipline, corporate partners
cooperating on a project, etc.) who, at least part of the time, share a common digital
geographic information language and share common spatial feature definitions. This implies
a common world view as well as common abstractions, feature representations, and metadata.
The feature collections that conform to the Information Community's standard language,
definitions, and representations belong to that Information Community.
Keep in mind that the details of the OGIS Information Communities Model have not, at
the time of this writing, been fully developed and approved by the OGIS Project Technical
Committee for inclusion in the OGIS detailed specification. The detailed specification and
DCP implementation specifications may differ from this description in significant ways.)
[ Table Of Contents ] [ Previous
Chapter ] [ Previous Section ] [ Next
Chapter ] [ Next Section ]
6.2 Basic Assumptions
Below are the basic assumptions underlying the OGIS Project's concept of Information
Communities.
[ Table Of Contents ] [ Previous Chapter ]
[ Previous Section ] [ Next Chapter ]
[ Next Section ]
6.3 Catalogs, Traders, and Semantic Translators
In the OGIS Information Communities
Model, Information Communities
rely on the use of special registries that contain manually derived
semantic models which enable a mapping of terms and/or definitions
from one Information Community to another.
Individual Information Communities'
datasets are bounded by a body of shared context and semantics.
Foreign Information Communities'datasets have different context
and semantics, but two bodies of context and semantics can be
reconciled to some degree so that data sharing
is possible. Each Information Community is free to negotiate relationships
with one or more foreign Information Communities to share
some or all of their data, as follows:
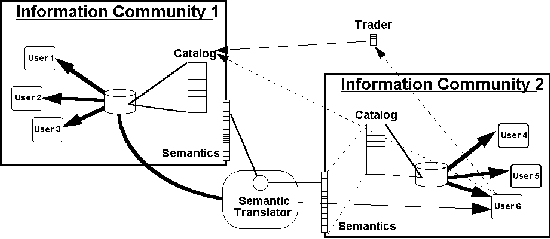 Figure 6-1 Catalogs list featurefeature collectionfeature
collections held by an Information Community. Facilities such as Traders (a
non-geodatageodata-specific DCPDCP service) give out-of-community data seekers a Catalog summary and
a pointer to an Information Community that has geodata to shareshare.
A Semantic TranslatorSemantic Translator automatically
translates semanticssemantics, enabling the target
Information Communitytarget Information Community to
make use of the source Information Communitysource Information
Community's information (to the degree that the source Information Community's
semantics can be translated into the target Information Community's semantics).
Figure 6-1 Catalogs list featurefeature collectionfeature
collections held by an Information Community. Facilities such as Traders (a
non-geodatageodata-specific DCPDCP service) give out-of-community data seekers a Catalog summary and
a pointer to an Information Community that has geodata to shareshare.
A Semantic TranslatorSemantic Translator automatically
translates semanticssemantics, enabling the target
Information Communitytarget Information Community to
make use of the source Information Communitysource Information
Community's information (to the degree that the source Information Community's
semantics can be translated into the target Information Community's semantics).
Figure 6-1 provides one picture of data integration between Information Communities.
Information Communities 1 and 2 each have one (or perhaps more) Catalogs which are the
basic means for geodata discovery and access within the Information Community.
Catalogs are collections of entries, each of which describes and points to a feature
collection which is represented here with a disk storage symbol. (See previous chapter for
a discussion of feature collections.) Catalogs, like databases and database tables,
provide a structured view of selected information and provide both a synopsis and a
roadmap to a feature collection or a data set that an application can use. Information
Communities may make Catalogs and their feature collections readable by out-of-community
data seekers, perhaps advertising them in traders. (See Section 7-8.)
By the definition of Information Community, all features contained in all of an
Information Community's feature collections are consistent in terms of their semantics.
(That is to say, the features conform to the same schema.) So users 1, 2, and 3 can trust
data contained in Information Community 1's catalogs to conform to Information Community
1's set of semantics, and users 4, 5, and 6 can trust data contained in Information
Community 2's catalog to conform to Information Community 2's set of semantics.
User 6, seeking additional information not available with Information Community 2, uses
a trader to discover that Information Community 1 may have helpful data. A look at
Information Community 1's catalog confirms that the desired data is indeed available, so
User 6 acquires the data, and in the process the Semantic Translator (which Information
Community 2 has configured with the cooperation of Information Community 1) automatically
translates the semantics. Of course, as the rest of this chapter explains, the translation
is only as good as the semantic mapping configured into the Semantic Translator.
Information Communities can also intersect, and clearly they often will, because any
two groups of geodata users are highly likely to have some common feature definitions and
feature collections and some different feature definitions and feature collections.
Similarly, one Information Community is a subset of another Information Community if all
of its feature definitions and all of its feature collections are subsets of those of a
larger Information Community.
There are now, and will undoubtedly continue to be organizations that maintain base
sets of geographic information whose definitions and meaning are shared across a group of
communities with otherwise distinct interests and semantics. If the USGS, for example,
were principal steward of a feature collection including geodetic network, topography and
hydrography for the U.S., and if a particular state's geology office were authorized to
develop new geodata of these types while maintaining the USGS's strict semantic standards,
the state's geology office would be an Information Community that would be a subset of the
USGS Information Community for these particular types of geodata.
For many purposes, partial data sharing and/or ad hoc data sharing will be quite
adequate, and it will be common. For example, a user may find through a Trader that
Information Community 1 has land use data for New York State. The Trader may be no more
specific than that. If Information Community 1 exposes its semantic data and its catalogs
to the general public, the out-of-community user can determine whether Information
Community 1 uses acceptable semantics for land use data, and whether particular data is
available. The semantics are acceptable and the data is available, so the user obtains
data from Information Community 1, without negotiation or discussion, and without benefit
of semantic translation. All of this could be done and is being done to a degree with the
World Wide Web instead of a Trader, and without OGIS. In Technical Committee discussions,
this kind of data access is called "pillaging," in contrast to data integration
achieved through a Semantic Translator.
With OGIS interfaces available in a variety of data access products, but without
Semantic Translators, users will share data as they do today, except that the OGIS
interfaces will make queries more powerful, make data access much faster and easier, and
make it possible for heterogeneous applications to access data held in heterogeneous
databases. OGIS interfaces will even discipline and facilitate "data fusion"
methods that convert, for example, some of the information in remote sensing images into
GIS thematic map layers that conform to a Base Information Definition. But without
Semantic Translators, semantic mismatch will need to by addressed by metadata standards
and inter-group coordination alone. Metadata standards
and intergroup coordination are an essential beginning, and work of this kind done now
will make it easier to configure Semantic Translators later.
It is frankly difficult to predict what the Information Communities picture will look
like ten years from now. It may happen (because the Net will be so big, because
Information Communities will be so complex and fragmented, and because there will be so
many sources of data) that groups that recognize themselves as Information Communities
will publish their geodata offerings in Traders, but the primary way in which others will
get that data will be "pillaging." That is, in this scenario data will usually
be acquired from a source Information Community on an ad hoc basis with little use of
well-tuned Semantic Translators developed and maintained through communication and
cooperation. More optimistically, it may happen that the maintenance and use of Semantic
Translators will become an essential part of a new global culture, one of the ways in
humans will constructively employ automation while interacting professionally to organize
a world that seems likely without such cooperative efforts to become increasingly chaotic.
The Information Communities concept may even be applied to systems for supporting
intergroup communication in non-geographic information circles.
In the next section, we look at some of the reasons for the chaos of the current
geodata semantics situation, to give potential OGIS developers an appreciation of the
scope of the problem. Virtually all the experienced geoprocessing software developers who
learn about OGIS believe that it is our best hope for solving the problem, but none of
them expect it to be easy. Clearly the cooperative manual process of building feature
dictionaries and Semantic Translators needs to be understood and promoted, and the
following discussion illuminates that process. Chapter 7 goes into greater detail about
Catalogs, Traders, and Semantic Translators in an explanation of the OGIS Services Model.
[ Table Of Contents ] [ Previous
Chapter ] [ Previous Section ] [ Next
Chapter ] [ Next Section ]
6.4 The Information Community Concept - Like Human Language
This section presents six levels of semantic mismatch. Semantic translators will be
designed which will indicate to the user how much data is being lost or questionably
placed, according to which of these levels applies at the time of attempted data
integration. Semantic Translators will not hide the tough decisions from users, even
though they will make the data conversion effortless.
To begin to understand the reasons for the complexity of the problem of data sharing,
it is useful to consider the close analogy between human language and spatial/temporal
computing.
Individuals sharing a context such as a professional society or an institutional
culture usually use a common human language to describe that context and to adhere to a
similar frame of reference in regard to it. They see the world through the same eyes and
characterize it using shared descriptors. Standardization of meanings facilitates
unimpeded, accurate communication.
For instance, doctors are likely to communicate more effectively with one another than
with petrochemical engineers or physicists who each rely on their own highly stylized
language to convey specialized information. Within the community of doctors, subsets of
specialists share vocabulary and skills which are not found across the community of
doctors at large. Communication within the sub-groups is specialized and efficient in
regard to the area of specialization that defines the group.
The complexity of this picture deepens as we see how each individual and institution
belongs to multiple groups. Consider two ways in which the federal bureaucracy can be
diagrammed: One model might be a department drawn with a single box for each agency and a
box for each division within each agency and so on. The top level box representing the
federal government constitutes a "root" Information Community representing a
corporate culture that is ubiquitous within the federal government and which is common to
all the participants. As the model is traversed from top to bottom an increasing number of
Information Communities emerge, sharing an increasingly specialized body of information
and semantics.
Taking a lateral view of the same diagram, based on function rather than organization
affiliation, consider the subset of all federal employees who are responsible for
accounting related to travel. Under this functional view there is a particular set of
concerns and tasks which is shared by a majority of this group in regard to administering
travel. In fact, in many respects a travel administrator in the USDA might be more closely
linked, in terms of information and semantics, to a travel administrator in the EPA than
to a colleague in the next office and the same agency whose primary job is inventory
control.
Common language, common conceptual model, and common meaning create semantic integrity
which in turn makes effective, unambiguous communication possible. These are the factors
which combine to define individual Information Communities, and which create the semantic
separation between Information Communities.
In perfect information sharing, information is exchanged with no degradation or loss of
meaning. Within a community that shares a language, a common set of definitions, and a
consistent conceptual model, lossless transmission of data can occur. However, as the
language, the definitions, and/or the conceptual model diverge between groups, information
sharing is imperfect and information is lost unless specific steps are taken to control
the process.
Logically, there are at least three distinct cases in which information may be lost
when communicating between different language groups, and by analogy, between Information
Communities:
- 1) In the first case, definitions and concepts are shared but there is no common
language between the two groups, or the groups share a common language but use
dramatically different dialects. This problem is corrected through simple translation
using a bi-directional mapping between the two languages. As long as the languages
themselves are stable and there is a 1:1 relationship between relevant terms this mapping
solution supports effective communication. For instance, if A and B want to talk about
logistics and the overland transportation of goods and A refers to trucking and B knows
the large vehicles as lorries, they can agree that the mapping of "truck" =
"lorry" will be used to communicate this concept.
- 2) In the second, somewhat more abstract case, a stable base of definitions for terms is
not shared between the communities. Correcting for this requires a direct mapping of
shared definitions plus a set of interpretations for terms that can't be mapped. Where
there is a 1:M mapping of definitions between communities, generalization and a consequent
loss of information will occur when mapping multiple, specific definitions to one more
general definition. For example, an Inuit using an Inuit language which may have more than
a dozen nouns that refer to different kinds of snow will not be able to convey subtle yet
important distinctions about snow when speaking with someone whose language has only one
word for snow.
- 3) Finally, there is the case in which basic concepts are not shared between the
communities. For instance, communicating in regard to snow or mass transportation
technology would be difficult if both parties didn't have at least some notion or concept
of these things. In the event that such a basic prerequisite for communication is not in
place it is very difficult, if not impossible, to share information.
When applying these insights to geodata sharing it is important to keep in mind that
geographic feature definitions become more specialized as we focus more finely on narrow
applications. For instance, we all can agree on a general definition of a road, but four
different GIS Information Communities will see four distinctly different phenomena
carrying with them very different sets of information. To the traffic network analyst the
road is a vector with a series of defining attributes which might include width,
impedance, lane numbers, sidewalks, signals, and intersections. To the remote sensing
specialist the road represents a particular spectral reflectance value that guarantees
that it is neither a wetland nor a cultivated agricultural area. To the cartographer the
road represents a mapping feature which must be characterized using a specific combination
of color, style and label in order to conform with a rigid rule base established for
roads. To the civil engineer, the road has compacted soil, gravel base, storm drains, and
paving material, as well as cadastral boundaries and many other characteristics.
It is precisely these kinds of semantic anomalies and conceptual inconsistencies that
the OGIS Information Communities Model addresses.
What the Geodata Model, by itself, Doesn't Do -Two Examples
The following examples illustrate the need for the Information Community Model:
Paved with Good Intentions -One Example of Open Geodata Model's Limitations
A cul-de-sac (a usually short road segment terminating in an enlarged turn-around area)
instance, expressed using the Open Geodata Model, clearly exposes the geometry that
establishes the path of the road on the face of the Earth. There may be additional
information in the form of attribute values attached to attribute names that are exposed,
such as:
Attribute Name Attribute value
surface material #2 grade asphalt
width (meters) 10
Maintainer Park and Recreation Dept.
Last maintained 10/12/92
In this example, the meaning of the attribute values is made clear, it appears at first
glance, through the use of careful attribute names. However, additional explanation is
required to ensure that precise meaning has been conveyed.
The attribute value "#2 grade asphalt" assumes the existence and
accessibility of a reference or authority that maintains exact definitions and conformance
tests for paving materials. Further, this assumes a technology that enables such
definitions to be published, managed and supported in accordance with regularities or
standards that are known within a community. (OGIS must provide a way to allow the
community that published the road segment information to refer to the authority that
establishes such standards).
The attribute value "10" is more subtle. There are several issues: Is
the value "10" rounded up or down? What are the allowed values of the
widths of roads within the community that exposed this feature? Is the value "10"
chosen from a "domain of valid widths," such as {6, 8, 10, 12, 14, 18, greater
than 20}? Is the number "10" an integer, or is it floating point, or is it
ASCII? Would it be correct to infer that the width of the road is 10 meters plus or minus
one millimeter? Does the value 10 meters refer to the width of the pavement, the width of
the right-of-way, the width of the narrowest spot along the segment, the average width,
the width between the curbs, or the width of the largest object that can move along the
road? OGIS must provide a technology that allows the community that exposed the road
segment to explain, in structured and/or natural language, the semantic meaning of the
value "10," and the meaning of the attribute name "width
(meters)."
The attribute value "Park and Recreation Dept." also needs
explanation. What does "maintainer" mean, exactly? How does one interact with
the "Park and Recreation Dept."? OGIS will support communication of such
explanations.
The date 10/12/92 could refer to the maintenance of the road itself, the maintenance of
some subset of the road, or the maintenance of some aspect of the feature collection in
which the road segment is represented. OGIS will provide a way to allow the provider of
the feature to expose sufficient semantics to resolve such questions.
There are additional ambiguities in the road segment cul-de-sac instance. For example:
the "dead" end of the segment may be represented in different ways:
- With a small circle representing a turn-around that may have its own attributes
- With a point that carries an "end-of-road" attribute
- By attaching an attribute to all road segments that flags cul-de-sacs
- By a digitizing convention that states cul-de-sacs are digitized so that they are
directed toward their "dead" end.
There are many other possible representations.
Furthermore, there is an even deeper question: what is the threshold for collection of
a cul-de-sac instance (used during the creation of the feature collection)? Are instances
of very short "dead end" road segments (say 10 feet long) represented as
cul-de-sacs in the feature collection? What are the capture criteria? If a feature
collection contains one cul-de-sac instance, can one assume all such instances are
present? What are the completeness characteristics of the feature collection?
OGIS must provide a technology that allows these conventions and characteristics to be
exposed and explained. Without such explanation, information sharing cannot be trusted
because the receiver of the Information Cannot know fully what the sender intended. Part
of the problem can be addressed by metadata,
but the real answer is to annotate the attributes
of features with descriptions to encourage the
use of numbers with physical units attached as a basic type when
referring to physical measurements.
A Bridge too Far -Another Example of the Open Geodata Model's
Limitations
A user may be interested in bridges and their lengths. However,
a feature collection with
no "bridge" feature type may contain instances of the
following feature types: viaduct, overpass, trestle,
catwalk, culvert, underpass, tunnel, and causeway. Moreover, each
of these may have an attribute called length. The user may need
to know how length is measured in each instance: from what structural
member to what other structural member, and to what accuracy.
OGIS must provide a technology that make is possible for Information
Communities to codify all possible
elements of such varied sets. OGIS technology can then be used
to expose the attributes of these elements programmatically
and to structure ways in which the attributes can be presented
and explained to the user.
Data Sharing Examples
In this section a series of examples are presented which illuminate
the assumptions developed in the previous section and attempt
to convey the diversity which is inherent in the
way geographic information is perceived and used.
Water, water everywhere: a hydrologic example
A system of feature class definitions within a distinct
Information Community is usually described in terms of a feature/attribution
schema. The following examples of inter-community
feature/attribute schema translations illustrate the conceptual
interaction of two Information Communities
which coexist within the same discipline.
Hydrography, according to the Department of Defense Glossary of
Mapping, Charting, and Geodetic Terms, is "the science which
deals with the measurements and description of the physical features
of the oceans, seas, and lakes, and their adjoining coastal areas,
with particular reference to their use for navigational purposes."
Hydrographic data has an important geospatial component. Two well-known
systems of feature class definitions used to describe
features within the hydrographic discipline are the S-57 Object
Catalogue, and the Feature and Attribute Coding Catalog (FACC).
The S-57 Object Catalogue is part of the IHO Transfer Standard
For Digital Hydrographic Data developed by the International Hydrographic
Organization. The FACC is part of the Digital Geographic Exchange
Standard (DIGEST) developed through an international cooperative
effort by the member nations of the Digital Geographic Information
Working Group (DGIWG).
Both of these schemes have a robust ontology of hydrographic features
and attributes to support geospatial use of these
data, though each is used for a slightly different purpose. The
S-57 Object Catalogue is primarily intended to support the visual
display component of electronic charts on board commercial sea-going
ships, and is used in the United States by the Department of Commerce
in producing digital hydrographic charts for the Electronic Chart
Display Information System (ECDIS). The FACC, as part of DIGEST,
was developed to support broadly applicable geospatial analysis
requirements, and is used in the United States primarily by the
Department of Defense in the generation of the Defense Mapping
Agency's Vector Product Format (VPF) products, including the Digital
Nautical Chart (DNC). Semantic translation between the two schemes
may be necessary to support the exchange of hydrographic data
under international exchange agreements aimed at updating and
improving the hydrographic charts and safety of navigation information
produced and maintained by both communities.
In translating between two feature class definition
schemes, there are at least six different results that can occur.
Let's look at some examples of these results in terms of translations
that might take place between feature classes in the S-57 Object
Catalogue and the FACC. (These schemes are used in these examples
for illustrative purposes only and an endorsement or critique
of either scheme should not be inferred.)
These are six general cases of feature class translation
results. To achieve true interoperability
between the feature class definition schemes of two different
Information Communities, other more
complex considerations apply. Though the semantic intent of a
feature may be consistent across two feature class definition
schemes, the content of their supporting attribution schemes may
be divergent from one another to a great degree. Even when the
attribute sets for two comparable feature classes in different
schemes match to a large degree, there are still opportunities
for loss of attribute information. A clear example of this is
the lack of support for undefined or indeterminate values in many
of the coded value attributes in the S-57 Object
Catalogue. Most of these attribute sets contain the same values
and corresponding meanings as their counterparts in the FACC,
with the exception of a code to indicate that the attribute was
not, or could not be, measured. For instances where attribute
information is undefined or indeterminate, a significant loss
of information is incurred when translating from the FACC to the
S-57 Object Catalogue in such cases.
Other measurement-based considerations will have an impact on
the semantic interoperability of feature
class and attribute definition schemes. Even if the feature class
and attribute definitions match exactly across two different schemes,
the feature's method of capture, as well as its method of representation
or portrayal, may be different, thus introducing uncertainty or
loss of information into the translation. The
former issue is concerned with the rules for feature data capture
for input into a digital geodatabase. Guidelines that specify,
for example, whether an analyst should delineate an area feature
by its perimeter, by its corner points, or by some other criteria,
will ultimately have an effect on the quality of the feature data
integration between two Information Communities,
especially if their expectations for that integration are different.
The latter issue relates to rules for feature data representation
in the geodatabase used by the Information Community. Guidelines
that specify whether a feature will be stored as a point, line,
or area, or some other complex geometric construct, also have
an effect on the quality of feature data integration between the
two Information Communities. If an area feature from one Information
Community is translated for use in another Information Community
that only supports a point representation for that feature, the
detailed areal extent information is not recoverable in the target
Information Community without
some kind of lineage metadata to accompany the exchange.
These are all significant challenges to achieving semantic interoperability between the
feature class and attribute definition schemes used by a diverse collection of geospatial
Information Communities. OGIS mechanisms must address how these challenges are met to
ensure efficient and accurate mediation of distributed, heterogeneous geospatial metadata
and feature class schema.
A Federal Agency Example
The structure of the federal bureaucracy provides many examples
of individual Information Communities
which use geodata and geoprocessing technology to help them fulfill
their mission. In the following discussion we examine an example
developed using the Bureau of Land Management as a sample Information
Community.
The BLM's Automated Land & Minerals Record System (ALMRS)
project is transitioning a pen & paper based records system
into a database & GIS system. The ALMRS land
status subprogram tracks ownership, management, rights, and limitations
(known as segregations) on U.S. land. The spatial descriptions
include a grab-bag of metes & bounds, township/range/section
rectangles, and modern surveys. "Land Status" could
be considered an IC. Other Information Communities
that might be interested in land status data could be mineral
exploration companies, real estate developers, or other government
land agencies (like the U.S. Forest Service). We will limit our
discussion of this hypothetical Information Community to describing
the attribute and geodata they use, and what information
other Information Communities might want to know about it.
Attribute Information That Might Populate the ALMRS Semantic
Translator
Land status tracks the surface & subsurface rights and segregations
on land. This data includes vast domains of possible values. The
allowed domains would be good candidates for the Semantic Translator.
For example, some of the 112 possible rights are "CALCIUM",
"CALICHE", "CINNABAR", "CLAY", "COAL",
"OIL & GAS", "PUMICE", "SALMON",
"TIMBER", "TIMBER IN PERPETUITY", etc. Some
surface segregations are "CLOSED TO AGRICULTURAL LAWS",
"CLOSED - DESERT LAND ENTRY"; subsurface segregations
include "ASPHALTIC MATERIAL", "GEOTHERMAL",
"SUBJECT TO SEC. 24 OF FPA". "Surface
Management Agency" has about 2400 possible values.
The system must track the dates of acquisitions, releases, terminations,
withdrawals, etc. to derive the cumulative rights, etc. To derive
the cumulative values for land status, the system follows complex
rules to determine which rights supersede others, and which areas
they apply to. These rules might be good candidates for the Semantic
Translator.
Also, given the dynamic nature of ownership, rights, etc., warnings
that the data gets re-derived on a regular basis should be in
the Semantic Translator. Other Information
Communities accessing this information
need to know how and when to update their information.
If rights or segregations on nominally located parcels (explained
below) cannot be resolved through the rules, they are flagged
as "COMPLEX". Any default values in the domain
like "COMPLEX" should be explained in the Semantic Translator,
that is, "This is not a real world value,
but an indication of ...".
Spatial Information that Might Populate the ALMRS Semantic
Translator
The initial system can only resolve rectangular "PLSS"
locations, also known as township/range/section/aliquot descriptions.
Assumptions about this geodata should be included
in the Semantic Translator. For example,
the smallest aliquot division possible determines the maximum
resolution of the data.
Non-rectangular data, like special surveys, must be "nominally"
located to one or more rectangular PLSS parcels. Assumptions about
these nominal locations should be stated in the Semantic Translator.
For example, special mineral surveys are nominally located at
a maximum resolution of a 1/4,1/4 section. Therefore, the actual
location of a survey cannot be known with any greater precision.
[ Table Of Contents ] [ Previous Chapter ]
[ Previous Section ] [ Next Chapter ]
6.5 Conclusions
Semantic differences between geographic features
and attributes used by different groups impose
the most difficult obstacle to data sharing,
as the foregoing examples and discussion indicate. The OGIS Information
Communities Model
offers a path toward overcoming this obstacle. New technologies
restructure our behavior, for better or worse, often without much
planning. Members of the OGIS Project are thinking carefully about
the system of human communications they propose to rationalize
and leverage with technology. Information Community technology,
if developed and delivered correctly, will structure both data
access and collaborative metadata
conformance efforts. Both kinds of activity will become easier, more efficient, and more
comprehensive. Metadata
conformance achieved through configuring Semantic Translators
will be particularly rewarding because the painstaking efforts
of the participants will be highly leveraged, in terms of future
benefit deriving from the automated systems, by the configured
software mechanisms.
In the next section we look at the OGIS Services Architecture,
in which OGIS distributed computing services critical to Information
Communities are described.
[ Table Of Contents ] [ Previous Chapter ]
[ Previous Section ] [ Appendix A. ]
[ Next Section ]
7. The OGIS Services Model
The OGIS Services Model is a
set of interoperable component services that developers will use
to build applications that have a geospatial component: The range
of geographic applications encompasses all problems for which
one wishes to model the Earth and then use the model to solve
these problems. As developers implement products with OGIS interfaces,
interoperable geographic applications will be composed of components
from the OGIS Services Model and other supporting and compatible
information services. OGIS Services Model components provide:
- The means by which Open Geodata Model
data types can be collected to form complex
models, queried for selections of subpart, and cataloged for sharing
(both internal and external to Information Communities).
- Mechanisms for defining and creating Information Communities
(described conceptually in Chapter 6 and in technical detail in
this chapter) and for developing linkages between these communities.
- The means by which Open Geodata Model
data types, user-defined data types, and
other capabilities (defined in this chapter) can be defined and
their operations executed.
The specific types developed for the OGIS Services
Model do not comprise a model of real
world facts (an essential model)
but a specification model of software
intended to provide the above capabilities.
The following sections outline each of these component types
and their relationships. In a specific implementation the processes
and/or code objects of the system being implemented
may not match in a one-to-one manner with the components outlined
in the specification model. Finally,
the reader should note that the specific capabilities listed are
not meant to be a complete and final set. Services may be extended,
added, or removed in the course of OGIS Project specification
writing.
[ Table Of Contents ] [ Previous Chapter ]
[ Previous Section ] [ Appendix A. ]
[ Next Section ]
7.1 Features, Their Schema, and The Feature Registry
In Chapter 5 we discussed the relationship between features
and their constituent property sets. Basically, features are made
up of their properties, which can be geometric,
semantic, or descriptive in nature. Figure 7-1 shows the relationship
between an instance (called "aFeature") of the Feature
type and a schema instance (called
"Feature") of the type FeatureSchema
that describes the property set for that feature
type. Note that every element of the schema defines an element
in the property set and that there is a one-to-one correspondence.
If a property set does not conform exactly to a schema, then the
feature is not properly that feature type. All features that conform
exactly are of the feature type defined by the schema. Features
provide access to their schema. Feature schemas define all aspects
of a feature type including geometric components (including associated
spatial temporal reference systems), semantic
components, and metadata (an element of a Base Information Definition). Lastly, note that
the Feature instance has an identity (this topic is covered in section 5.4.1). In the
figure we have chosen to depict the value of this identity as a string that refers to an
Internet node ("nsdi.gov"), a database name ("BigDB"), and a
hexadecimal number that uniquely identifies this particular feature within the storage
system being utilized (0x0c5f).
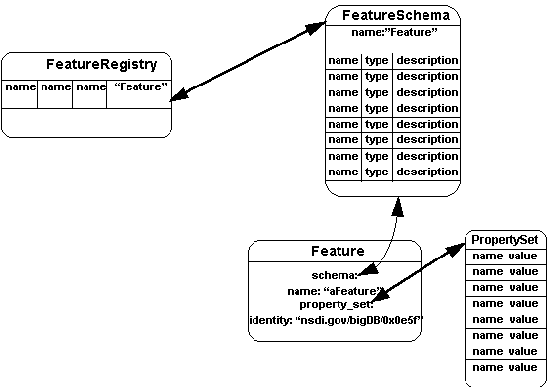 Figure 7-1 Features, Schemas,
and the Feature Registry
Figure 7-1 Features, Schemas,
and the Feature Registry
Feature schemas are stored in a registry (called a Feature Registry), so that
they can be shared and reused. This aspect is especially important in the context of an
Information Community, where the definitions of features have been agreed to as a
component of standardization for interoperability. The entries in the Feature Registry
contain a name and a schema. Although not shown in the diagram, feature registries are
factories for features. This means that, once a feature schema has been selected and an
input set of properties that correspond to the elements of the schema are provided, the
registry can be used to create an instance of a feature.
Although not shown, a single FeatureSchema can be defined in many registries and many
registries can exist in one Information Community. If multiple feature registries exist
within an Information Community there should be some notion of an authoritative feature
registry. As a matter of fact, this issue comes up over and over again with all indexing
structures within an Information Community. Thus registries are referenced within an
Information Community (see section 7.2 for the details).
[ Table Of Contents ] [ Previous
Chapter ] [ Previous Section ] [ Appendix
A. ] [ Next Section ]
7.2 Access to Geodata via the Catalog
In Chapter 5 we pointed out that features are the central concept of the Open Geodata
Model. The granularity of access to data under database management control is at the
level of features. Somehow the geodata in databases must be exposed (as a Feature)
to OGIS-based applications or OGIS-based application environments. This is achieved by
means of the indexing system known as a Catalog. Another catalog may also be
referenced as a Catalog Entry (an element of a catalog). Catalogs can be thought of
as "buckets" that contain features and other buckets. An abstract example, is
depicted in Figure 7-2. Notice that, for every level of depth, the items enclosed in
ellipses are catalog entries for the level above.
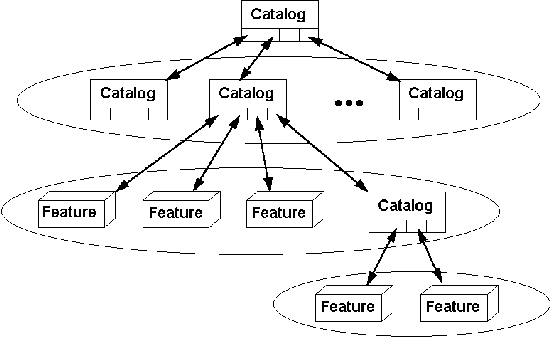 Figure 7-2 An
abstract Catalog example
Figure 7-2 An
abstract Catalog example
Each catalog entry has a schema that conforms, at least partially, to a schema that is
maintained as part of the catalog (this schema is called the Catalog Entry Schema).
That is, each catalog entry must have properties that match the schema elements contained
in the Catalog Entry Schema as part of its property set. An application developer (or a
user of a Base Information Definition configuration tool) configures a Catalog Entry
Schema to refer to whatever information is considered necessary by the application
developer or by the Information Community or Communities in which the data is being
shared. The Catalog Entry Schema can be thought to contain the metadata required for the
contained catalogs and features to conform to a
Catalog. In section 7.9 we will show how this schema can be
used to build valid catalog queries.
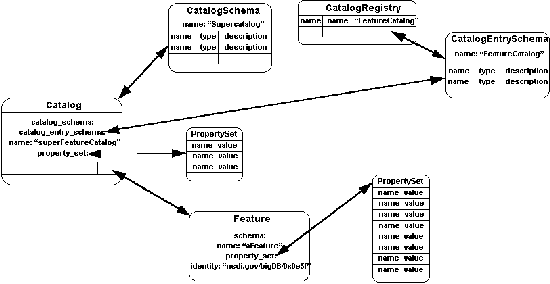
Figure 7-3 provides an example of the above. The Catalog named
"superFeatureCatalog" has
the CatalogEntrySchema called "FeatureCatalog".
"FeatureCatalog" defines a schema having
two elements (we don't really care what they are for this example).
The Catalog called "superFeatureCatalog" has two catalog
entries, a feature called
"aFeature" and a catalog called "subCatalog".
"aFeature" has a schema (called "Feature")
that has two elements that correspond to "FeatureCatalog"
and a property set that has elements exactly matching the elements
defined in "Feature" and thus has two elements that
also match "FeatureCatalog". "aFeature" is
said to conform to the catalog entry schema
of "superFeatureCatalog" because
it has elements that completely correspond to "FeatureCatalog".
"subCatalog" has exactly the same explanation with differing
names. Notice that in both cases the property sets of the contained
entries must conform to the catalog entry schema of the containing
catalog.
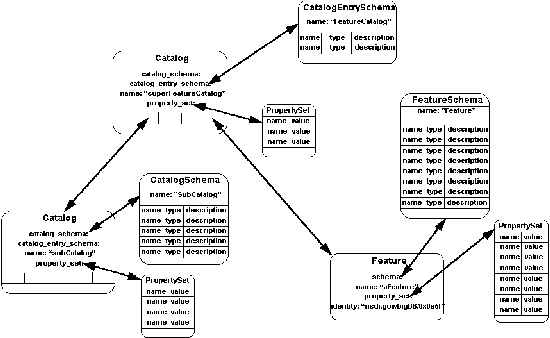 Figure
7-3 Relationships between Catalogs, Catalog Entry Schemas,
and Catalog Entries.
Figure
7-3 Relationships between Catalogs, Catalog Entry Schemas,
and Catalog Entries.
Many catalogs can exist within an application context and/or information
community. Using catalogs, application developers
can control which features are exposed within an
Information Community. Catalogs are created by a factory method
of a Catalog Registry (exactly analogous
to the Feature Registry capability). Figure 7-4 depicts the situation
using the relevant parts of Figure 7-3.
 Figure
7-4 Catalog Registry
Figure
7-4 Catalog Registry
Here we see that a catalog registry
contains named entries, each of which points to a valid catalog
entry schema. Providing the registry factory method the name of
a catalog entry schema, a catalog schema,
and a set of properties that exactly matches
the catalog schema will result in successful Catalog creation.
Once the catalog has been created it may be inserted into an appropriate
containing catalog (as long as its catalog schema conforms to
the catalog entry schema of the containing
catalog). Features created using the feature registry
factory method can also be inserted
into a containing catalog (as long as the features
schema conform to the catalog entry schema.
Here it is appropriate to deal with the issue of authoritative
indexing mentioned in section 7.1. Registries (of all kinds) are
referenced by catalogs (as alluded to in Figure 7-4, so that they
can be accessed by interacting with a catalog.
[ Table Of Contents ] [ Previous Chapter ]
[ Previous Section ] [ Appendix A. ]
[ Next Section ]
7.3 Master Catalogs and Bootstrapping
Up to this point we have seen two registries (one for feature
schemas and one for catalog entry schemas)
and the catalog. In application use these entities
must be locatable and, if more than one exists, they must either
be tied to some authoritative source or made accessible via some
other mechanism. As we mentioned in the last paragraph, the registries
are locatable via the catalogs. However, we still have the issue
of authoritative catalogs and bootstrapping.
This issue must be dealt with at the level of implementation,
but here we provide two options:
- If applications are interacting over a wide area, or across
many hosts within an information community, then an authoritative
"Master Catalog" with a "known"
location should be constructed that indexes all
other catalogs within the information community. This is straightforward
to build given the mechanisms in Section 7.2. The Master Catalog
should be initially locatable via a persistent handle.
- If applications are interacting locally, or within a local
area, then appropriate catalogs can be bootstrapped at startup
utilizing persistent handles accessible between the run times
of applications.
One or both of these mechanisms might become standardized within
the OGIS Project at some point in the future, but not until considerable
application experience can be brought to bear on the issues.
[ Table Of Contents ] [ Previous Chapter ]
[ Previous Section ] [ Appendix A. ]
[ Next Section ]
7.4 Spatial/Temporal Reference System Access
and Translation
Spatial/temporal reference systems used
within an information community must be made accessible for transformations
and for understanding geometries. Transformations will be needed
when:
- Users have a need to change spatial/temporal reference systems,
- The coordinate geometries connected with features are to be
understood,
- Information is shared between information communities using
differing spatial/temporal reference systems, or
- Implementations use differing parameter sets to implement
spatial/temporal reference systems.
This requirement means that spatial/temporal reference systems
must be defined in a common way (the exact methodology is beyond
the scope of this book, but can be found in OGIS) and these definitions
must be made available via some mechanism. This section defines
the mechanism used to register spatial/temporal reference systems
and the mechanism to transform features to create
otherwise identical features with different spatial/temporal reference
systems.
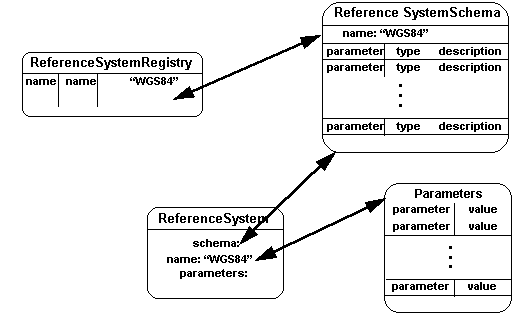
7.4.1 Spatial/Temporal Reference System Access
Figure 7-5 details the linkages between a spatial/temporal reference
system,
its definition, and a registry used to index spatial/temporal
reference system definitions.
The spatial/temporal reference system registry is referenced (like
feature and catalog registries) in
catalogs containing features that use the spatial/temporal
reference system definitions contained in the registry.
 Figure
7-5 Spatial/Temporal Reference System Access
Figure
7-5 Spatial/Temporal Reference System Access
7.4.2 Spatial/Temporal Reference System Transformation
In addition to providing a common registry of spatial/temporal
reference systems,
OGIS must also make available, as a common resource, a collection
of transforms that generate features with different
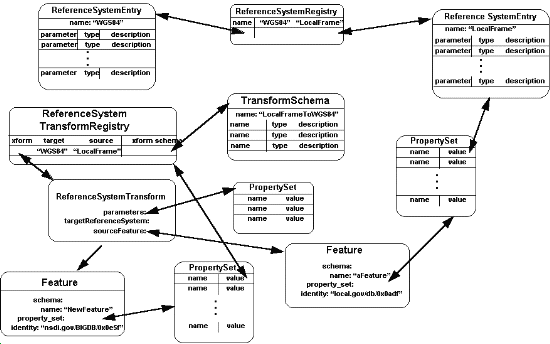
spatial/temporal reference systems. Figure 7-6 depicts both the
mechanism used to access spatial/temporal reference system transformations
and an example transformation. The four types in the
center of the figure detail the access mechanism. A Reference
System Transform Registry stores all of the parts needed to transform
a feature with geometric properties associated to a spatial/temporal
reference system (in this case "LocalFrame") to a feature
with exactly the same properties except the geometric properties
that have been transformed and now are associated with the new
spatial/temporal reference system (in this case "WGS84").
Notice that the transform registry maintains a reference to the
transformation "code" (called a Reference System Transform),
the source and target spatial/temporal reference systems, and
a transform schema. The transform schema defines
the properties of a transformation (usually transformation
parameters), providing a flexible mechanism for implementation
of more capable and generic transforms.
When a transform is invoked, it is provided with a set of transformation
properties (that match the Transform Schema)
and a source Feature (in our case "aFeature). The transform
can then construct the new feature (in this case
"aNewFeature" at lower left).
 Figure
7-6 Spatial/Temporal Reference System Translation
Figure
7-6 Spatial/Temporal Reference System Translation
Spatial/temporal reference system transformation
registries are referenced by spatial/temporal reference system
registries themselves. When inter- or intra- Information Community
transformations are needed, then the appropriate
transforms should be developed or purchased and installed by entering
them in the appropriate spatial/temporal reference system registry
(in other words, the registry in the target environment). Transforms
that are available in the source environment may also be used.
[ Table Of Contents ] [ Previous Chapter ]
[ Previous Section ] [ Appendix A. ]
[ Next Section ]
7.5 Semantic Translation
The Semantic Translator is a set of
types providing a mechanism for the translation
of features from Information Community to Information
Community. Chapter 6 describes the intended use and the need for
such a mechanism. The types presented here, like all the others
presented so far in this book, represent a consensus reached after
considerable discussion in the Technical Committee.
But unlike geodata modeling and distributed geodata access, automated
semantic translation has not been part of the mainstream academic
or commercial geoprocessing research agenda.
So, we expect early implementation of the types and associations
described below to lead to more discussion and perhaps to a revision
of the model.
7.5.1 Overview
As we stated in Chapter 6, an Information Community may agree
to work with a partner Information Community in the manual construction
of one or more semantic mappings which will be used to facilitate
one way or two way data sharing between
itself and its partner Information Community. This cooperative
task is mainly a matter of coming to agreement on the precise
meaning of each Feature, schema element by schema
element, and capturing the results of this work as a series of
Feature Translators.
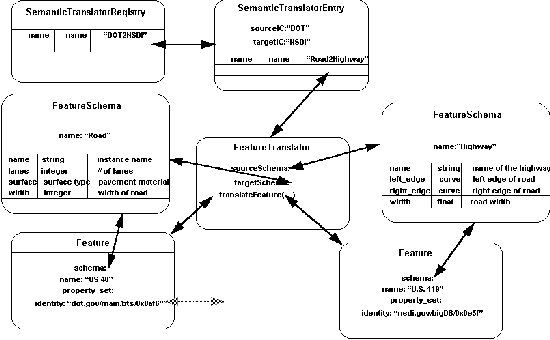
Within an integrating Information Community, a registry of Feature
Translators (called the SemanticTranslatorRegistry)
will exist, as shown in Figure 7-7. A SemanticTranslatorRegistry
contains a set of definitions for translating Features from a
source Information Community
Catalog to a target Information Community
Catalog. Thus a SemanticTranslatorRegistry contains many SemanticTranslatorDefinitions
that map features in a source Catalog to features
in a target Catalog by defining all of the necessary FeatureTranslators.
FeatureTranslators provide the ability to translate a single Feature
from a source FeatureSchema to a target FeatureSchema.
 Figure
7-7 Semantic Translator
Figure
7-7 Semantic Translator
Figure 7-8 is an OMT specification model
diagram which illustrates the relationships among SemanticTranslatorRegistry,
SemanticTranslatorDefinitions, and FeatureTranslators.
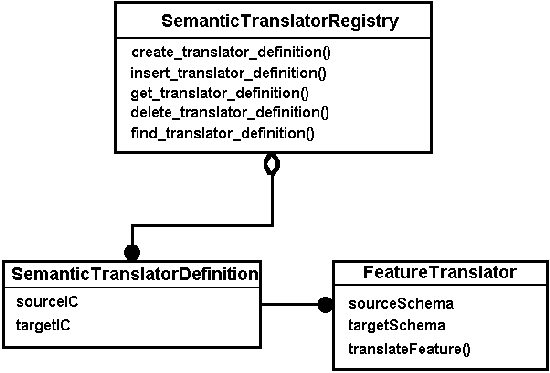 Figure
7-8 Semantic Translator and Registry
Model
Figure
7-8 Semantic Translator and Registry
Model
7.5.2 The FeatureTranslator Type
The FeatureTranslator type encapsulates the functionality required
to translate a Feature from one feature schema
to another feature schema. The interface includes:
- sourceSchema, the FeatureSchema
of the source Feature
- targetSchema, the FeatureSchema
of the target Feature
- translateFeature(), which performs the actual translation
of a particular instance of feature type sourceSchema
into a particular instance of feature type targetSchema.
The translateFeature() operation
must contain all of the necessary rules, calculations, mappings,
or whatever else it takes to perform the translation.
In this way very simple to very complex translations can be handled
via the same interface. It is anticipated that additional (value-added)
services will be implemented in products that automate, to a greater
or lesser degree, the job of developing FeatureTranslators.
7.5.3 The SemanticTranslatorRegistry
A semantic translator registry is a
repository for named semantic translator definitions. It functions
as a clearinghouse for feature translation
capabilities in Information Communities
that are, in whole or in part, an integration of other Information
Communities. A SemanticTranslatorDefinition
contains a set of FeatureTranslations for the integration of features
from a single source Information Community
to a target Information Community.
The SemanticTranslatorRegistry
supports the following functionality:
- Inserting a SemanticTranslatorDefinition into a SemanticTranslatorRegistry
- Getting a SemanticTranslatorDefinition out of the SemanticTranslatorRegistry
- Finding a SemanticTranslatorDefinition
in of the SemanticTranslatorRegistry,
given some search criteria
- Deleting a named SemanticTranslatorDefinition
from a SemanticTranslatorRegistry
- Creating a FeatureTranslator given the appropriate input parameters
[ Table Of Contents ] [ Previous Chapter ]
[ Previous Section ] [ Appendix A. ]
[ Next Section ]
7.6 Operation Registry
7.6.1 Overview
Now that we have addressed automated geodata access,
spatial/temporal reference system
conversion, and semantic translation, we look
directly at how OGIS supports operations on geographical data
in distributed environments. Distributed geoprocessing
operations can be part of a Database Management System (DBMS)
or separate from a DBMS. For instance:
- A DBMS might define operations on new data types
that it contains.
- A vendor might sell a set of geoprocessing
operations that users can use on their own data.
- Developers might define new geoprocessing
operations as part of the applications that they are building.
End users, however, do not want to know where an operation is
defined. In addition, a geoprocessing operation
might call another without knowing whether it has been built into
the system or defined by the user.
Most object models make the definition of operations part of the
definition of objects. But that makes it hard to
define operations intended to work on existing data. Those models
also choose an operation based on the class of one object, but
many geoprocessing operations depend on the
classes of more than one object. For example, intersecting a circle
and a line is different from intersecting a polyhedron and a line,
which is different from intersecting a point and a fractal cloud,
which is different from intersecting an arc and a chain. In the
worse case, introducing a new kind of geometry
requires defining how it intersects with each of the other geometries.
But in a distributed system, it is not even possible to know all
the kinds of geometries, since there might be many new kinds of
geometries being defined simultaneously.
To solve these problems, OGIS supports an object model in which
operations are not necessarily part of objects and
can be selected based on the classes of more than one object.
This is a multi-operation object model, and it uses a type system
similar to that developed by Chambers and Leavens
(see Bibliography).
7.6.1.1 Concepts
Types in OGIS are defined as a set of related operations. They
are different from the implementation of an object, which is a
Class.
Each type has a unique identifier. (It is a subtype
of Identity). A type can be the subtype of one or more other types,
but the subtype graph is acyclic: that is, there can be no circular
or recursive associations from child back to
parent. The union of two types is their common supertype;
the intersection of two types is their common subtype.
The type system defines a set of interfaces. Each interface has
a set of operations and attributes.
Attributes are basically simplified definitions of operations.
An attribute definition is a simplified way to define a pair of
accessor operationsone that allows read access and one that allows
write access to the attribute value. A read-only attribute
defines an operation that is a read-only accessor for the attribute
value. Each operation has a name, a return type, and a sequence
of parameter types. Operations do not have to have
unique names.
For example, the following interface (expressed in OMG
IDL, for convenience):
interface ExampleInterface {
attribute float att_a;
readonly attribute boolean is_ok;
long count_item(in AnotherInterface input);
}
defines four operations. These operations are (also expressed
in OMG IDL):
float get_att_a(in ExampleInterface o);
void set_att_a(in ExampleInterface o, in float a);
boolean get_is_ok(in ExampleInterface o);
long count_item(in ExampleInterface o, in AnotherInterface input);
There are usually many operations with the same name. A operation
t is compatible with a operation s if s and
t have different names, if the return type of t
is a subtype of the return type of s, or
if one of the parameter types of s is not a
subtype of the corresponding parameter type in t. A set
of operations is compatible if each operation in the set is compatible
with every other operation in the set.
For example, suppose Geometry has subtype Curve,
which has subtype LineString. The following set
of operations would be compatible:
Geometry intersect(in Geometry a, in Geometry b)
LineString intersect(in LineString a, in LineString b)
LineString intersect(in LineString a, in Curve b)
Curve intersect(in Curve a, in Curve b)
Each program has a current set of operations. An operation call
is legal only if there is a operation in the current set with
the same name and whose parameter types are supertypes
of the types of the actual arguments of the operation call.
The implementation of these operations and the connection between
operations and their implementations are discussed in the section
on the OperationRegistry.
Operations can be defined in DBMS's, be predefined
by the implementation of OGIS, or be defined by the developer.
But there must be a central OperationRegistry
that can decide which operation to select for a particular set
of arguments. The OperationRegistry not only registers operations,
it also registers implementations. It invokes services and can
define new services or add to existing services.
The OperationRegistry must ensure the
consistency of its information. To this purpose, the OperationRegistry
must certify that all registered operations are compatible.
The OperationRegistry is responsible for
invoking operations. The OperationRegistry services an invocation's
request in the following manner:
- First, it selects all operations with the same name and with
parameter types that are each a supertype of the types
of the actual arguments.
- From this set of operations , it selects those for which no
other operation in the set fulfills these two conditions: having
all its parameter types as subtypes of the operation
in question, and having at least one that is not equal.
- If there is no selected operation then the operation call
is in error. If there is only one such operation, it is invoked.
- If there are several such operations with identical types
then the OperationRegistry must pick one
based on location or assigned priority. (This part
of the specification is incomplete at the time of this writing.)
- If there are several such operations but they do not have
identical types then there are at least two operations
M and N whose parameter types are supertypes of the actual argument
types but M has a parameter type that is strictly a subtype
of the corresponding parameter type of N, and N has a parameter
type that is strictly a subtype of the corresponding parameter
type of M. For the time being, we will consider these to be errors.
Many multi-operation based systems pick an arbitrary order, such
as choosing the operation whose first argument is the most specific.
7.6.1.2 Operation Registry Model
This section outlines the use model for the Operation Registry.
Figure 7-9 depicts the components of interest in a single Operation
Registry interaction. They are the client of the interaction,
the Operation Registry itself, and an object that implements the
operation to be performed. The use model has four steps (some
of which may be repeated many times in a single interaction).
They are:
- Query the Operation Registry to return the operation(s) that
match some client-defined criteria. The criteria will initially
be limited to the name of the operation the client wishes to invoke.
- The Operation Registry returns matches
to the client for selection.
- Once the client has selected the operation,
the client calls the create_operation
interface on the operation Registry to create an Operation object.
- The Operation Registry creates the Operation
object and returns the reference to the client for subsequent
request and response interaction.
The client may then:
- Prepare the operation for execution by supplying values for
all parameters to the operation,
- Execute the operation, once prepared, either synchronously
or asynchronously,
- Check the status of asynchronously executed operations to
determine if they are completed (and if completed, if they failed
or succeeded) or terminated,
- Terminate asynchronously executed operations, and
- Get the results of successfully completed operations or the
exception values for failed operations.
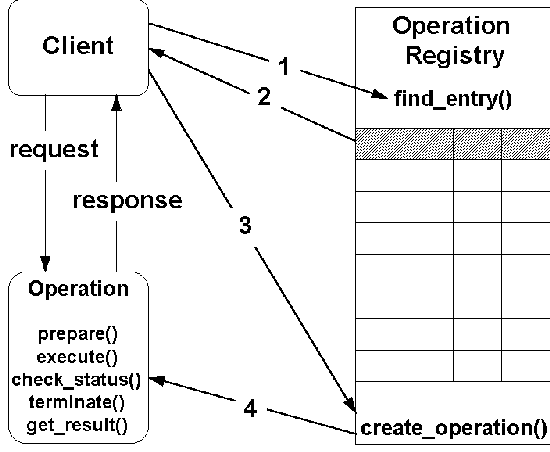 Figure
7-9 Use model for Operation Registry interaction
Figure
7-9 Use model for Operation Registry interaction
Figure 7-10 illustrates the relationships among Operation, OperationSchema,
OperationEntry, and OperationRegistry.
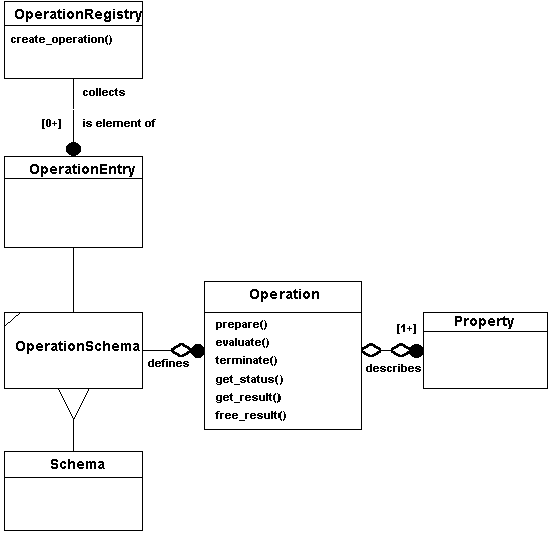 Figure
7-10 Operation and Operation Registry Specification Model
Figure
7-10 Operation and Operation Registry Specification Model
7.6.2 The OperationRegistry Type
An operation registry is a repository for named operation definitions
(each called an OperationEntry). It functions
as a clearinghouse for the operations available within Information
Communities. A OperationEntry defines
a set of attributes that are shared in common
with all instances (like class variables in the C++ sense). These
attributes include:
- The name of the operation in its fully qualified form (this
is necessary because types in OGIS won't necessarily
match implementation classes).
- The description of the operation.
- The schema for Operations defined by this OperationEntry.
- An implementation-specific handle that allows an application
to use exactly the same object instance to perform operations
using exactly the same implementation (this is necessary because
two different implementations of the same operation might exist
within an Information Community).
- A boolean indicating whether or not the operation changes
the value of its arguments (this is necessary to determine whether
the operation can be used in a query).
- A boolean indicating whether or not the OperationEntry
is an alias for another operation. If it is, then the next operation
must return the fully qualified name for the operation aliased.
- The fully qualified name of the operation being aliased.
The OperationRegistry type supports the
following functionality:
- Inserting an OperationEntry to an OperationRegistry.
- Getting an operation entry from an OperationRegistry
based on its name.
- Finding operation entries based on some search criteria.
- Deleting operation entries from an OperationRegistry.
- Creating Operations given the appropriate input parameters.
[ Table Of Contents ] [ Previous Chapter ]
[ Previous Section ] [ Appendix A. ]
[ Next Section ]
7.7 Type Registry
7.7.1 Overview
As with any distributed object system, metadata about types
must be accessible and updatable so that developers can create applications which portably
interoperate with each other and with core components. Here we refer the reader to the
CORBA specification (specifically, the Interface Repository) and to the COM specification
and the Type Library portion of OLE Automation.
The following types are meant to abstract these mechanisms so that implementation
independence can be gained at the OGIS level.
The Type Registry enables users to install new types in the shared environment, and it
enables other users to see what new types have been implemented and to create an instance
of a new type that has become available in the shared environment. We anticipate that
users will be able to buy components from different vendors and install them into an
environment where they can be immediately useful without recompilation. The Type Registry
is very much like the operation registry, except that the only new operation enabled when
a TypeFactory instance is created is the creation of an instance of that type. Once the
capability to create a new type becomes available through the Type Registry, then the
Operation Registry support discussed in the previous section will also be available.
This section outlines the use model for the Type Registry. Figure 7-11 depicts the
components of interest in a single Type Registry interaction. These components are: the
client of the interaction, the Type Registry itself, and an object that implements a
factory for the needed Type. The use model has four steps (some of which may be repeated
many times in a single interaction). They are:
- Query the Type Registry to return the type factory that matches some client-defined
criteria. The criteria are initially limited to the name of the type the client seeks to
create.
- The Type Registry returns the matching Type Entry to the client.
- The client calls the create_type_factory interface on the
Type Registry to create a TypeFactory object.
- The Type Registry creates the Type Factory object and
- returns the reference to the client.
- The client calls the create_instance interface of the TypeFactory object to create an instance of the type.
- The TypeFactory object creates the instance and
- returns the reference to the client.
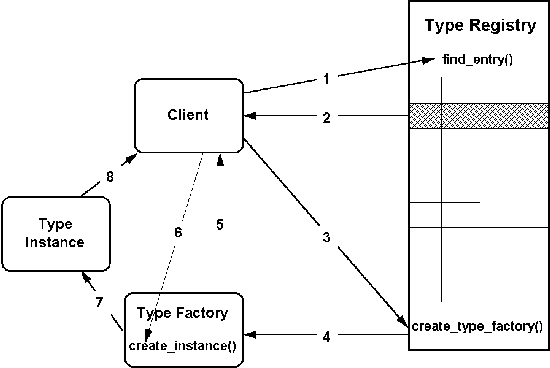 Figure 7-11 Use
model Type Registry interaction
Figure 7-11 Use
model Type Registry interaction
Figure 7-12 illustrates the relationships among TypeFactory, TypeSchema, TypeEntry, and
TypeRegistry.
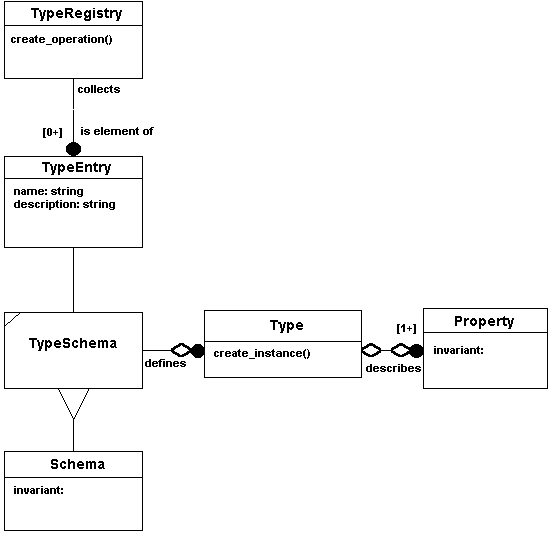 Figure 7-12
TypeFactory and Type Registry Specification Model
Figure 7-12
TypeFactory and Type Registry Specification Model
7.7.2 The TypeFactory Type
The TypeFactory type supports the following functionality:
- Get the name of the TypeFactory
- Get the TypeSchema for the Type that the factory will create
- Get the properties of the TypeFactory
- Create an instance of the Type
7.7.3 The TypeRegistry Type
A type registry is a repository for named type definitions (each called a TypeEntry).
It functions as a clearinghouse for the types available within Information Communities. A
TypeEntry defines a set of attributes that are shared in common with all instances (like
class variables in the C++ sense). The attributes include:
- The name of the Type that the factory defined by the entry will create
- The description of the Type
- The schema for the TypeFactory
The TypeRegistry supports the following functionality:
- Inserting an TypeEntry into a TypeRegistry
- Getting a type entry of a TypeRegistry
- Finding a type entry given some search criteria
- Deleting a TypeEntry from a TypeRegistry
- Creating a TypeFactory given the appropriate input parameters
[ Table Of Contents ] [ Previous
Chapter ] [ Previous Section ] [ Appendix
A. ] [ Next Section ]
7.8 Traders
A trading service, or Trader, provides a mechanism for locating items of interest, such
as Catalogs and their contents. Traders mediate import and export offers between Catalogs
and their potential users. Catalog descriptions are "exported" to a Trader which
can then mediate between the Catalogs and potential Catalog clients (who want to
"import" a reference to a Catalog that suits their requirements).
Like Catalogs and Features, Traders also have associations with PropertySets that
function to describe the properties of the import and export offers within the Trader. A
TraderSchema imposes the required structure on the PropertySets used by the Trader to
establish a template for the Trader. In other words, the Properties contained in the
TraderSchema must exist in a PropertySet that supports the Trader. A Trader also has a
query facility which allows the selection of services based on the service type and/or
other properties of the services.
The notion of trading services is an area of widespread interest within and among
other Information Technology disciplines (in other words, outside of the OGIS Project).
Standards for trading services are emerging from ongoing work by other standards
organizations. The OGIS project will leverage these standards when appropriate and will
attempt to influence the requirements for trading services through liaison with other
standards bodies. We introduce the concept here, because we feel it is a valuable future
capability, especially in terms of inter-Information Community "discovery:"
[ Table Of Contents ] [ Previous
Chapter ] [ Previous Section ] [ Appendix
A. ] [ Next Section ]
7.9 Queries
Queries in the OGIS environment are supplied by a set of types collectively known as
the OGIS Query Service. The query service types are the basic mechanisms for retrieving
information from feature collections and catalogs.
The OGIS Query Service is modeled closely after the OMG Query Service (see Object
Management group 1995, OMG Tech Comm Doc 95-1-1, Object Query Service Specification). The
primary types are:
Figure 7-14 depicts the Collection and Iterator types and their relationship. The types
are defined in detail below (see sections 7.9.1 and 7.9.2, respectively). A Collection may
have any number of Iterators that are actively iterating over the collection, but these
iterators depend on the existence of the Collection. In fact, if the collection changes,
then the iterator becomes invalid.
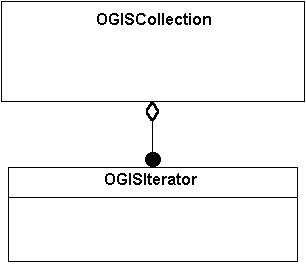 Figure 7-14 The Collection
Specification ModelSpecification Model
Figure 7-14 The Collection
Specification ModelSpecification Model
7.9.1 The Collection Type
The Collection type defines operations to:
- Add elements
- Replace elements
- Remove elements
- Retrieve elements in a collection
- Create iterators for traversing the collection
The element type of a collection can be any type of value: primitive, constructed, and
object data types. Note that a given Collection may have multiple iterators defined on it.
7.9.2 The Iterator Type
The Collection type can create an iterator called an Iterator. The Iterator type
defines operations to:
- Access and navigate through elements of a collection
- Reset the iteration, and
- Test for completion of an iteration
7.9.3 The QueryEvaluator Type
The QueryEvaluator type defines operations for evaluating queries. It also returns the
type(s) of query language(s) it supports, including its default query language. The
QueryEvaluator manages an implicit collection of persistent objects. The query evaluator
has an operation that returns a list of the data types which will be returned by the
query. In other words, if the query were to be executed and an iterator were to be created
on the resulting collection, then an invocation of the next operation on the iterator
would return a sequence of values. The describe operation tells what actual data
types would appear in the sequence for that particular query. The evaluate operation
evaluates the query, performs the required query processing, and returns a collection
containing the results.
7.9.4 The Query Type
The Query type defines four operations that can be performed on an instance of a query:
- Prepare a query for execution
- Execute a query
- Determine the preparation and execution status of a query
- Obtain the results of a query (a Collection of sequences of values as given by the
describe method on the QueryEvaluator type)
The Query type can identify the QueryManager which created it.
7.9.5 The QueryManager Type
The QueryManager is a more powerful form of QueryEvaluator which enables creation and
direct interaction with a Query object.
The QueryManager is a Query factory that provides for defining the input query. If the
query language type is not specified, a default query language is assumed. If the query
language type is specified it must be supported by the QueryManager, otherwise an error is
flagged. If the query syntax or semantics are incorrect or if the input parameter list is
incorrect, an error is reported. The parameters to the Query factory provide the values
for any dynamic variables appearing in the query string. If these values are provided for
the factory then any values provided for the prepare and execute operations of Query type
will be ignored.
[ Table Of Contents ] [ Previous
Chapter ] [ Previous Section ] [ Appendix
A. ] [ Next Section ]
7.10 The Query Model
We have explained in detail the components of the Query Service, but we need to
describe the model so that a better understanding of the actual process of executing a
query is understood. OGIS supports two models, a simple one-step operation and a more
complex, but powerful multi-step operation.
Figure 7-15 depicts both of these operations. For the simple process only steps 0 and
12 are needed. For the complex model, the client is assumed to take the role of the Query
Evaluator in the figure and steps 1 through 11 are needed. The process is as follows:
- A client tasked to perform a query prepares an appropriate query string in a selected
query language and invokes the evaluate operation on the Query Evaluator.
- The QueryEvaluator then finds a QueryManager that can handle the query language of the
query string passed by the client and invokes the create_query operation. If the
complex process is in use, then the client has performed these tasks.
- The QueryManager creates a Query object.
- The QueryManager returns the Query object handle to the QueryEvaluator (or to the query
client if the complex process is in use).
- The QueryEvaluator (or query client) invokes the prepare operation to ready the
Query. Note that this step is only necessary if the invoking entity has not provided
parameters for queries containing variables.
- The Query object returns control to the QueryEvaluator (a query client).
- The QueryEvaluator (or query client) invokes the execute operation on the Query
object, specifying details of how to perform the query (such as whether the query is to be
executed synchronously or asynchronously, etc.).
- The Query object immediately returns control to the QueryEvaluator (a query client) if
the query is asynchronous, else it completes the query execution and returns control at
that point.
- If the query was performed asynchronously, the QueryEvaluator can check the status of
the query during execution to determine whether the query is complete or has failed for
some reason. If the query is performed synchronously, then the status of the query can be
checked using the get_status operation.
- The get_status operation will return either an indication of success or an
indication of failure and the reason(s) for failure.
- If the query has been successfully executed, then the get_result operation can be
invoked.
- The get_result operation returns the Collection of results to the QueryEvaluatorQueryEvaluator (or the query client).
- If the simple model is used the QueryEvaluatorQueryEvaluator
returns either the Collection of results or a failure indication along with the reason(s)
for failure.
 Figure
7-15 Query Model
Figure
7-15 Query Model
[ Table Of Contents ] [ Previous
Chapter ] [ Previous Section ] [ Appendix A. ]
7.11 Query Service Issues
7.11.1 Query Languages
In general, the properties of a feature can be classified into four categories:
- Spatial extent of the feature
- Temporal extent of the feature
- Structured attributes, such as used in traditional databases
- Textual attributes, such as lengthy descriptive material
It is necessary to be able to use any or all of these categories in query conditions.
The only requirement that is unique for OGIS for a query language is:
Any operation on any type will be available from within the query language.
The spatial extent of a feature is normally a Geometry. For example, query conditions
on the spatial extent will typically need to use the following Boolean operations as
defined from the types for coordinate geometry and geometry:
- Intersect(Geometry1, Geometry2) = Geometry1.Intersect(Geometry2)
- Contain(Geometry1, Geometry2) = Geometry1.Contain(Geometry2)
- Equal(Geometry1, Geometry2) = Geometry1.Equal(Geometry2)
- ContainedIn(Geometry1, Geometry2) = Contain (Geometry2, Geometry1) =
Geometry2.Contain(Geometry1)
Query conditions will also need to use the BufferZone(Geometry, Distance) operation, or
perhaps an extended set of Boolean operations:
- IntersectBufferZone(Geometry, Geometry, Distance) =
Intersect ( Geometry, BufferZone(Geometry, Distance))
- ContainsBufferZone(Geometry, Geometry, Distance)
- ContainedInBufferZone(Geometry, Geometry, Distance)
The temporal extent of a feature is normally a TemporalObject, which can be defined as
a finite set of non-intersecting time intervals (where an interval may be unbounded on
either or both ends). Query conditions on the temporal extent will typically need to use
boolean intersects, contains and equals operations.
Query conditions on structured attributes will typically need to use the types of
operations which are supported by such well known query languages as SQL or OQL.
Query conditions on textual attributes will typically involve "appears_in(keyword,
text)" or "keyword_of(keyword, text)" operations of the sort which lie at
the heart of full-text indexing/searching systems.
Thus, a query language for querying feature collections should support spatial,
temporal and textual object types, as well structured attributes, and should support the
operations described above for these extended data types, as well as the usual operations
for structured attributes.
The language OQL defined in the Object Database Standard (ODMG-93) already supports
these extended data types and operations, in the sense that these data types and
operations can be defined in the object definition language ODL and then used in OQL
queries. However, in order to achieve acceptable performance when querying over large
feature sets, it will be necessary to have data managers which have built-in knowledge of
these data types and operations and which provide support for them, in the sense of
providing efficient indexing mechanisms for executing queries involving them, rather than
just having these data types and operations defined at the application level.
In its present form the language SQL does not support these extended data types and
operations.
Thus, there is a need for extensions to SQL and OQL which explicitly include these
extended data types and operations, and there is a need for enhanced relational and object
data managers which support them. Hopefully, these features will soon be included in the
standards for SQL and OQL.
In the meantime, implementations of query services may have to support only limited
forms of such extended data types and operations and may have to impose restrictions on
the ways in which they can appear in query expressions. Such limited forms of support are
preferable to no support at all. One example of such a limited form of support would be a
query manager which supports only rectangular extents, all in a common spatial/temporal
reference system, and which requires that the "where" clause of a query must be
a conjunction of terms, each of which contains only one type of condition (spatial,
temporal, attribute, or textual).
7.11.2 Query Schema
Ideally, the object types which appear in the query schema for a feature collection
would match the data types of the properties in the features of the feature collection.
However, this is not always possible. For example, the data types of the properties in a
feature may be arbitrarily complex, and SQL supports only a fairly limited set of data
types. One can represent very complex data types with the relational data model, but the
result is a representation, not an exact match of data types.
The query schema for each feature collection should be accessible through the query
manager itself, using the standard query facilities. In other words, the query schema
should be made available as data, using a standard representation for schema information.
This is common practice for relational databases, and in fact the SQL standard specifies
how the schema information should be represented in relational tables. A similar facility
should be provided for an OQL implementation.
Copyright © 1996, Open GIS Consortium, Inc.
 Figure 7-13 Query Service
Specification ModelSpecification Model
Figure 7-13 Query Service
Specification ModelSpecification Model